Automatic Relevance Determination Regression (ARD)¶
Fit regression model with bayesian_ridge_regression.
Compared to the OLS (ordinary least squares) estimator, the coefficient weights are slightly shifted toward zeros, wich stabilises them.
The histogram of the estimated weights is very peaked, as a sparsity-inducing prior is implied on the weights.
The estimation of the model is done by iteratively maximizing the marginal log-likelihood of the observations.
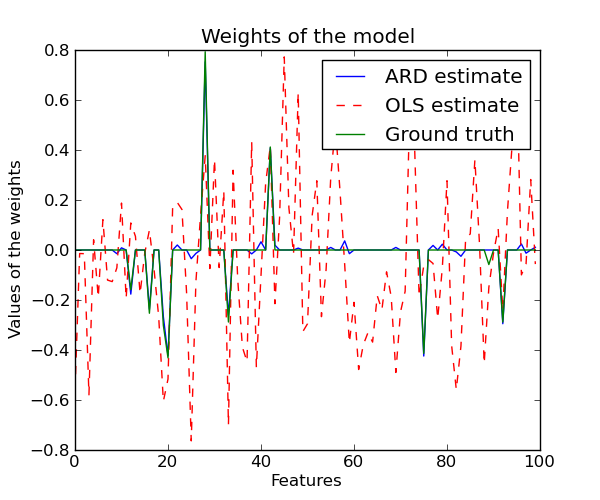
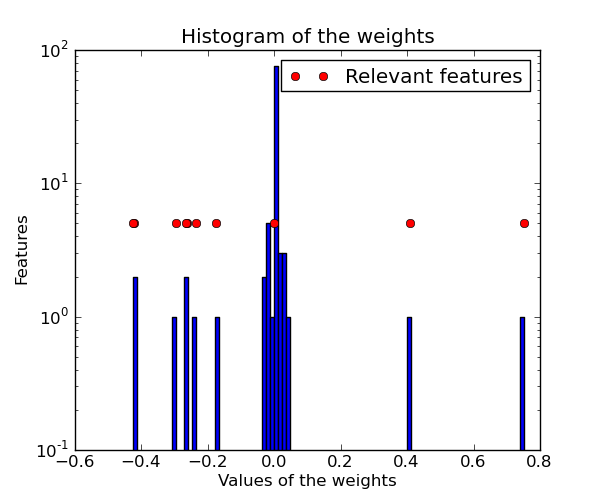
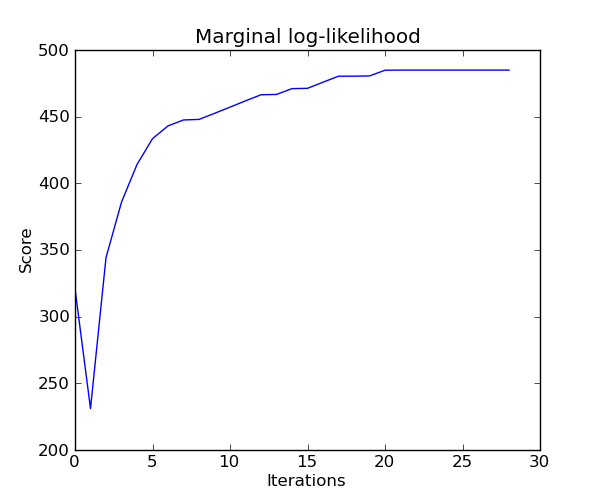
Python source code: plot_ard.py
print __doc__
import numpy as np
import pylab as pl
from scipy import stats
from sklearn.linear_model import ARDRegression, LinearRegression
################################################################################
# Generating simulated data with Gaussian weigthts
# Parameters of the example
np.random.seed(0)
n_samples, n_features = 100, 100
# Create gaussian data
X = np.random.randn(n_samples, n_features)
# Create weigts with a precision lambda_ of 4.
lambda_ = 4.
w = np.zeros(n_features)
# Only keep 10 weights of interest
relevant_features = np.random.randint(0, n_features, 10)
for i in relevant_features:
w[i] = stats.norm.rvs(loc=0, scale=1. / np.sqrt(lambda_))
# Create noite with a precision alpha of 50.
alpha_ = 50.
noise = stats.norm.rvs(loc=0, scale=1. / np.sqrt(alpha_), size=n_samples)
# Create the target
y = np.dot(X, w) + noise
################################################################################
# Fit the ARD Regression
clf = ARDRegression(compute_score = True)
clf.fit(X, y)
ols = LinearRegression()
ols.fit(X, y)
################################################################################
# Plot the true weights, the estimated weights and the histogram of the
# weights
pl.figure(figsize=(6, 5))
pl.title("Weights of the model")
pl.plot(clf.coef_, 'b-', label="ARD estimate")
pl.plot(ols.coef_, 'r--', label="OLS estimate")
pl.plot(w, 'g-', label="Ground truth")
pl.xlabel("Features")
pl.ylabel("Values of the weights")
pl.legend(loc=1)
pl.figure(figsize=(6, 5))
pl.title("Histogram of the weights")
pl.hist(clf.coef_, bins=n_features, log=True)
pl.plot(clf.coef_[relevant_features], 5*np.ones(len(relevant_features)),
'ro', label="Relevant features")
pl.ylabel("Features")
pl.xlabel("Values of the weights")
pl.legend(loc=1)
pl.figure(figsize=(6, 5))
pl.title("Marginal log-likelihood")
pl.plot(clf.scores_)
pl.ylabel("Score")
pl.xlabel("Iterations")
pl.show()