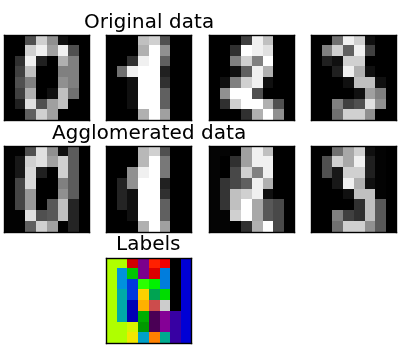
Python source code: plot_digits_agglomeration.py
import pylab as pl
from scikits.learn import datasets, cluster
from scikits.learn.feature_extraction.image import grid_to_graph
digits = datasets.load_digits()
images = digits.images
X = np.reshape(images, (len(images), -1))
connectivity = grid_to_graph(*images[0].shape)
agglo = cluster.WardAgglomeration(connectivity=connectivity,
n_clusters=32)
agglo.fit(X)
X_reduced = agglo.transform(X)
X_restored = agglo.inverse_transform(X_reduced)
images_restored = np.reshape(X_restored, images.shape)
pl.figure(1, figsize=(4, 3.5))
pl.clf()
pl.subplots_adjust(left=.01, right=.99, bottom=.01, top=.91)
for i in range(4):
pl.subplot(3, 4, i+1)
pl.imshow(images[i], cmap=pl.cm.gray,
vmax=16, interpolation='nearest')
pl.xticks(())
pl.yticks(())
if i == 1:
pl.title('Original data')
pl.subplot(3, 4, 4+i+1)
pl.imshow(images_restored[i],
cmap=pl.cm.gray, vmax=16, interpolation='nearest')
if i == 1:
pl.title('Agglomerated data')
pl.xticks(())
pl.yticks(())
pl.subplot(3, 4, 10)
pl.imshow(np.reshape(agglo.labels_, images[0].shape),
interpolation='nearest', cmap=pl.cm.spectral)
pl.xticks(())
pl.yticks(())
pl.title('Labels')