4.2. Manifold learning¶

Manifold learning is an approach to nonlinear dimensionality reduction. Algorithms for this task are based on the idea that the dimensionality of many data sets is only artificially high.
4.2.1. Introduction¶
High-dimensional datasets can be very difficult to visualize. While data in two or three dimensions can be plotted to show the inherent structure of the data, equivalent high-dimensional plots are much less intuitive. To aid visualization of the structure of a dataset, the dimension must be reduced in some way.
The simplest way to accomplish this dimensionality reduction is by taking a random projection of the data. Though this allows some degree of visualization of the data structure, the randomness of the choice leaves much to be desired. In a random projection, it is likely that the more interesting structure within the data will be lost.


To address this concern, a number of supervised and unsupervised linear dimensionality reduction frameworks have been designed, such as Principal Component Analysis (PCA), Independent Component Analysis, Linear Discriminant Analysis, and others. These algorithms define specific rubrics to choose an “interesting” linear projection of the data. These methods can be powerful, but often miss important nonlinear structure in the data.


Manifold Learning can be thought of as an attempt to generalize linear frameworks like PCA to be sensitive to nonlinear structure in data. Though supervised variants exist, the typical manifold learning problem is unsupervised: it learns the high-dimensional structure of the data from the data itself, without the use of predetermined classifications.
Examples:
- See Manifold learning on handwritten digits: Locally Linear Embedding, Isomap... for an example of dimensionality reduction on handwritten digits.
- See Comparison of Manifold Learning methods for an example of dimensionality reduction on a toy “S-curve” dataset.
The manifold learning implementations available in sklearn are summarized below
4.2.2. Isomap¶
One of the earliest approaches to manifold learning is the Isomap algorithm, short for Isometric Mapping. Isomap can be viewed as an extension of Multi-dimensional Scaling (MDS) or Kernel PCA. Isomap seeks a lower-dimensional embedding which maintains geodesic distances between all points. Isomap can be performed with the object Isomap.

4.2.2.1. Complexity¶
The Isomap algorithm comprises three stages:
- Nearest neighbor search. Isomap uses
sklearn.neighbors.BallTree for efficient neighbor search.
The cost is approximately
![O[D \log(k) N \log(N)]](../_images/math/0bb1f5705d1b4cb5f9b7241f529fddba23273795.png) , for
, for 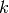 nearest neighbors of
nearest neighbors of 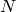 points in
points in 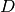 dimensions.
dimensions. - Shortest-path graph search. The most efficient known algorithms
for this are Dijkstra’s Algorithm, which is approximately
![O[N^2(k + \log(N))]](../_images/math/31e1150f8ab00e03d825eb22d563f494258bfa49.png) , or the Floyd-Warshall algorithm, which
is
, or the Floyd-Warshall algorithm, which
is ![O[N^3]](../_images/math/900bffafee75e1b9d075fde7979410a759469326.png) . The algorithm can be selected by the user with
the path_method keyword of Isomap. If unspecified, the code
attempts to choose the best algorithm for the input data.
. The algorithm can be selected by the user with
the path_method keyword of Isomap. If unspecified, the code
attempts to choose the best algorithm for the input data. - Partial eigenvalue decomposition. The embedding is encoded in the
eigenvectors corresponding to the
 largest eigenvalues of the
largest eigenvalues of the
 isomap kernel. For a dense solver, the cost is
approximately
isomap kernel. For a dense solver, the cost is
approximately ![O[d N^2]](../_images/math/44ff8882aaedb0d90ea661dcb275dfcf7c0038f5.png) . This cost can often be improved using
the ARPACK solver. The eigensolver can be specified by the user
with the path_method keyword of Isomap. If unspecified, the
code attempts to choose the best algorithm for the input data.
. This cost can often be improved using
the ARPACK solver. The eigensolver can be specified by the user
with the path_method keyword of Isomap. If unspecified, the
code attempts to choose the best algorithm for the input data.
The overall complexity of Isomap is
![O[D \log(k) N \log(N)] + O[N^2(k + \log(N))] + O[d N^2]](../_images/math/990c46631a02c6f20a15af03c70ee13693c4f446.png) .
.
- : number of training data points
- : input dimension
- : number of nearest neighbors
- : output dimension
References:
- “A global geometric framework for nonlinear dimensionality reduction” Tenenbaum, J.B.; De Silva, V.; & Langford, J.C. Science 290 (5500)
4.2.3. Locally Linear Embedding¶
Locally linear embedding (LLE) seeks a lower-dimensional projection of the data which preserves distances within local neighborhoods. It can be thought of as a series of local Principal Component Analyses which are globally compared to find the best nonlinear embedding.
Locally linear embedding can be performed with function locally_linear_embedding or its object-oriented counterpart LocallyLinearEmbedding.

4.2.3.1. Complexity¶
The standard LLE algorithm comprises three stages:
- Nearest Neighbors Search. See discussion under Isomap above.
- Weight Matrix Construction.
![O[D N k^3]](../_images/math/074e13babe7a81980a087cfd4c71d69c6ef0fabe.png) .
The construction of the LLE weight matrix involves the solution of a
.
The construction of the LLE weight matrix involves the solution of a
 linear equation for each of the local
neighborhoods
linear equation for each of the local
neighborhoods - Partial Eigenvalue Decomposition. See discussion under Isomap above.
The overall complexity of standard LLE is
![O[D \log(k) N \log(N)] + O[D N k^3] + O[d N^2]](../_images/math/f25c41ecaf087953402b078828ee8c6f486bcf45.png) .
.
- : number of training data points
- : input dimension
- : number of nearest neighbors
- : output dimension
References:
- “Nonlinear dimensionality reduction by locally linear embedding” Roweis, S. & Saul, L. Science 290:2323 (2000)
4.2.4. Modified Locally Linear Embedding¶
One well-known issue with LLE is the regularization problem. When the number
of neighbors is greater than the number of input dimensions, the matrix
defining each local neighborhood is rank-deficient. To address this, standard
LLE applies an arbitrary regularization parameter  , which is chosen
relative to the trace of the local weight matrix. Though it can be shown
formally that as
, which is chosen
relative to the trace of the local weight matrix. Though it can be shown
formally that as  , the solution coverges to the desired
embedding, there is no guarantee that the optimal solution will be found
for
, the solution coverges to the desired
embedding, there is no guarantee that the optimal solution will be found
for  . This problem manifests itself in embeddings which distort
the underlying geometry of the manifold.
. This problem manifests itself in embeddings which distort
the underlying geometry of the manifold.
One method to address the regularization problem is to use multiple weight vectors in each neighborhood. This is the essence of modified locally linear embedding (MLLE). MLLE can be performed with function locally_linear_embedding or its object-oriented counterpart LocallyLinearEmbedding, with the keyword method = 'modified'. It requires n_neighbors > out_dim.

4.2.4.1. Complexity¶
The MLLE algorithm comprises three stages:
- Nearest Neighbors Search. Same as standard LLE
- Weight Matrix Construction. Approximately
![O[D N k^3] + O[N (k-D) k^2]](../_images/math/8ef8a9d2f7ba0266cfce9a2ef0339880e60c0c3a.png) . The first term is exactly equivalent
to that of standard LLE. The second term has to do with constructing the
weight matrix from multiple weights. In practice, the added cost of
constructing the MLLE weight matrix is relatively small compared to the
cost of steps 1 and 3.
. The first term is exactly equivalent
to that of standard LLE. The second term has to do with constructing the
weight matrix from multiple weights. In practice, the added cost of
constructing the MLLE weight matrix is relatively small compared to the
cost of steps 1 and 3. - Partial Eigenvalue Decomposition. Same as standard LLE
The overall complexity of MLLE is
![O[D \log(k) N \log(N)] + O[D N k^3] + O[N (k-D) k^2] + O[d N^2]](../_images/math/58b96b103f3380efb60e88163d7ff45234bc6c51.png) .
.
- : number of training data points
- : input dimension
- : number of nearest neighbors
- : output dimension
References:
- “MLLE: Modified Locally Linear Embedding Using Multiple Weights” Zhang, Z. & Wang, J.
4.2.5. Hessian Eigenmapping¶
Hessian Eigenmapping (also known as Hessian-based LLE: HLLE) is another method of solving the regularization problem of LLE. It revolves around a hessian-based quadratic form at each neighborhood which is used to recover the locally linear structure. Though other implementations note its poor scaling with data size, sklearn implements some algorithmic improvements which make its cost comparable to that of other LLE variants for small output dimension. HLLE can be performed with function locally_linear_embedding or its object-oriented counterpart LocallyLinearEmbedding, with the keyword method = 'hessian'. It requires n_neighbors > out_dim * (out_dim + 3) / 2.

4.2.5.1. Complexity¶
The HLLE algorithm comprises three stages:
- Nearest Neighbors Search. Same as standard LLE
- Weight Matrix Construction. Approximately
![O[D N k^3] + O[N d^6]](../_images/math/6ea1cb7c15c3e5ad834b0fb34549b764f13890b6.png) . The first term reflects a similar
cost to that of standard LLE. The second term comes from a QR
decomposition of the local hessian estimator.
. The first term reflects a similar
cost to that of standard LLE. The second term comes from a QR
decomposition of the local hessian estimator. - Partial Eigenvalue Decomposition. Same as standard LLE
The overall complexity of standard HLLE is
![O[D \log(k) N \log(N)] + O[D N k^3] + O[N d^6] + O[d N^2]](../_images/math/8d7fa9e2b4599b4dc501426e5ed0c4ff25ceca3c.png) .
.
- : number of training data points
- : input dimension
- : number of nearest neighbors
- : output dimension
References:
- “Hessian Eigenmaps: Locally linear embedding techniques for high-dimensional data” Donoho, D. & Grimes, C. Proc Natl Acad Sci USA. 100:5591 (2003)
4.2.6. Local Tangent Space Alignment¶
Though not technically a variant of LLE, Local tangent space alignment (LTSA) is algorithmically similar enough to LLE that it can be put in this category. Rather than focusing on preserving neighborhood distances as in LLE, LTSA seeks to characterize the local geometry at each neighborhood via its tangent space, and performs a global optimization to align these local tangent spaces to learn the embedding. LTSA can be performed with function locally_linear_embedding or its object-oriented counterpart LocallyLinearEmbedding, with the keyword method = 'ltsa'.

4.2.6.1. Complexity¶
The LTSA algorithm comprises three stages:
- Nearest Neighbors Search. Same as standard LLE
- Weight Matrix Construction. Approximately
![O[D N k^3] + O[k^2 d]](../_images/math/e260aa4d522200a255b06dca42d69f1852612182.png) . The first term reflects a similar
cost to that of standard LLE.
. The first term reflects a similar
cost to that of standard LLE. - Partial Eigenvalue Decomposition. Same as standard LLE
The overall complexity of standard LTSA is
![O[D \log(k) N \log(N)] + O[D N k^3] + O[k^2 d] + O[d N^2]](../_images/math/4a66f1945d28d61ea8f51a74fad433334ea65f14.png) .
.
- : number of training data points
- : input dimension
- : number of nearest neighbors
- : output dimension
References:
- “Principal manifolds and nonlinear dimensionality reduction via tangent space alignment” Zhang, Z. & Zha, H. Journal of Shanghai Univ. 8:406 (2004)
4.2.7. Tips on practical use¶
- Make sure the same scale is used over all features. Because manifold learning methods are based on a nearest-neighbor search, the algorithm may perform poorly otherwise. See Scaler for convenient ways of scaling heterogeneous data.
- The reconstruction error computed by each routine can be used to choose
the optimal output dimension. For a -dimensional manifold embedded
in a -dimensional parameter space, the reconstruction error will
decrease as out_dim is increased until out_dim == d.
- Note that noisy data can “short-circuit” the manifold, in essence acting as a bridge between parts of the manifold that would otherwise be well-separated. Manifold learning on noisy and/or incomplete data is an active area of research.