4.3. Decomposing signals in components (matrix factorization problems)¶
4.3.1. Principal component analysis (PCA)¶
4.3.1.1. Exact PCA and probabilistic interpretation¶
PCA is used to decompose a multivariate dataset in a set of successive orthogonal components that explain a maximum amount of the variance. In the scikit-learn, PCA is implemented as a transformer object that learns n components in its fit method, and can be used on new data to project it on these components.
The optional parameter whiten=True parameter make it possible to project the data onto the singular space while scaling each component to unit variance. This is often useful if the models down-stream make strong assumptions on the isotropy of the signal: this is for example the case for Support Vector Machines with the RBF kernel and the K-Means clustering algorithm. However in that case the inverse transform is no longer exact since some information is lost while forward transforming.
In addition, the ProbabilisticPCA object provides a probabilistic interpretation of the PCA that can give a likelihood of data based on the amount of variance it explains. As such it implements a score method that can be used in cross-validation.
Below is an example of the iris dataset, which is comprised of 4 features, projected on the 2 dimensions that explain most variance:
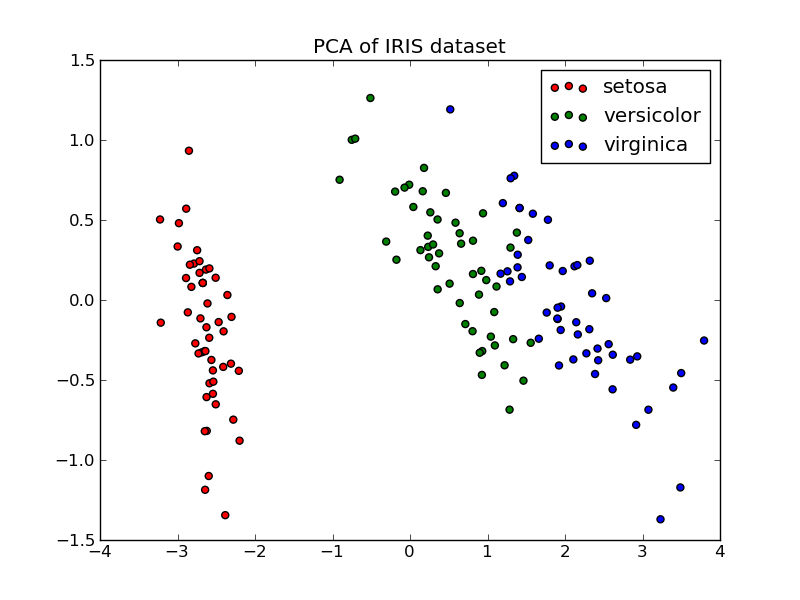
Examples:
4.3.1.2. Approximate PCA¶
Often we are interested in projecting the data onto a lower dimensional space that preserves most of the variance by dropping the singular vector of components associated with lower singular values.
For instance for face recognition, if we work with 64x64 gray level pixel pictures the dimensionality of the data is 4096 and it is slow to train a RBF Support Vector Machine on such wide data. Furthermore we know that intrinsic dimensionality of the data is much lower than 4096 since all faces pictures look alike. The samples lie on a manifold of much lower dimension (say around 200 for instance). The PCA algorithm can be used to linearly transform the data while both reducing the dimensionality and preserve most of the explained variance at the same time.
The class RandomizedPCA is very useful in that case: since we are going to drop most of the singular vectors it is much more efficient to limit the computation to an approximated estimate of the singular vectors we will keep to actually perform the transform.
RandomizedPCA can hence be used as a drop in replacement for PCA minor the exception that we need to give it the size of the lower dimensional space n_components as mandatory input parameter.
If we note 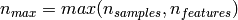 and
and
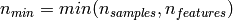 , the time complexity
of RandomizedPCA is
, the time complexity
of RandomizedPCA is 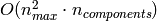 instead of
instead of 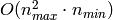 for the exact method
implemented in PCA.
for the exact method
implemented in PCA.
The memory footprint of RandomizedPCA is also proportional to
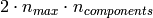 instead of
instead of 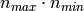 for the exact method.
for the exact method.
Furthermore RandomizedPCA is able to work with scipy.sparse matrices as input which make it suitable for reducing the dimensionality of features extracted from text documents for instance.
Note: the implementation of inverse_transform in RandomizedPCA is not the exact inverse transform of transform even when whiten=False (default).
References:
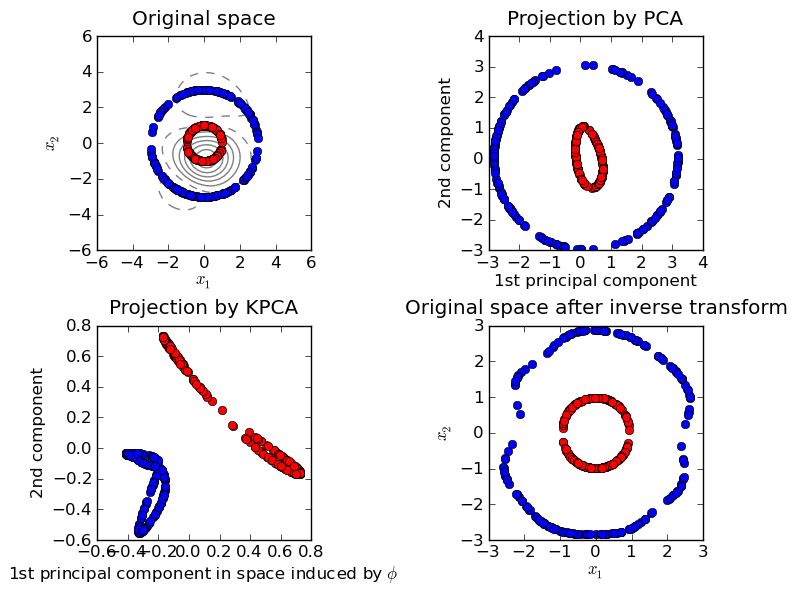
4.3.1.3. Kernel PCA¶
KernelPCA is an extension of PCA which achieves non-linear dimensionality reduction through the use of kernels. It has many applications including denoising, compression and structured prediction (kernel dependency estimation). KernelPCA supports both transform and inverse_transform.
Examples:
4.3.2. Independent component analysis (ICA)¶
ICA finds components that are maximally independent. It is classically used to separate mixed signals (a problem know as blind source separation), as in the example below:
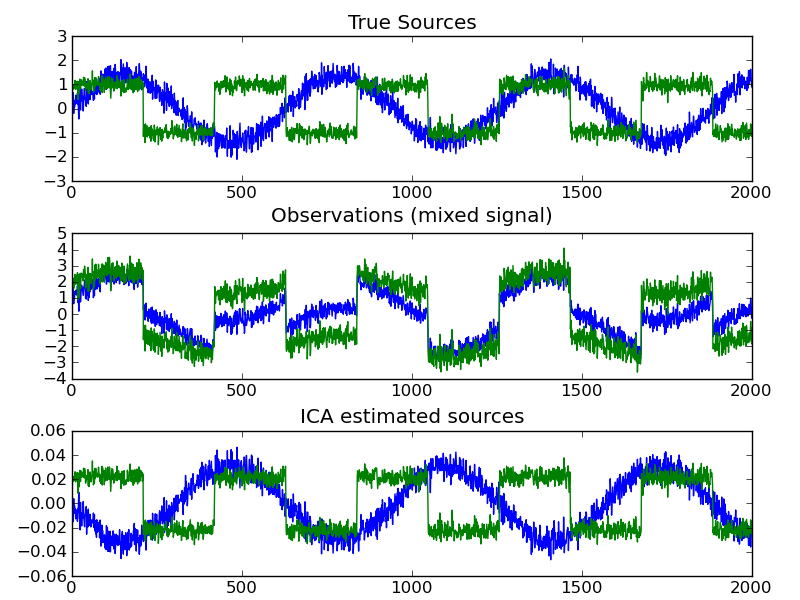
4.3.3. Non-negative matrix factorization (NMF)¶
NMF is an alternative approach to decomposition that assumes that the data and the components are non-negative. NMF can be plugged in instead of PCA or its variants, in the cases where the data matrix does not contain negative values.
Unlike PCA, the representation of a vector is obtained in an additive fashion, by superimposing the components, without substracting. Such additive models are efficient for representing images and text.
It has been observed in [Hoyer, 04] that, when carefully constrained, NMF can produce a parts-based representation of the dataset, resulting in interpretable models. The following example displays 16 sparse components found by NMF on the digits dataset.


The init attribute determines the initialization method applied, which has a great impact on the performance of the method. NMF implements the method Nonnegative Double Singular Value Decomposition. NNDSVD is based on two SVD processes, one approximating the data matrix, the other approximating positive sections of the resulting partial SVD factors utilizing an algebraic property of unit rank matrices. The basic NNDSVD algorithm is better fit for sparse factorization. Its variants NNDSVDa (in which all zeros are set equal to the mean of all elements of the data), and NNDSVDar (in which the zeros are set to random perturbations less than the mean of the data divided by 100) are recommended in the dense case.
NMF can also be initialized with random non-negative matrices, by passing an integer seed or a RandomState to init.
In NMF, sparseness can be enforced by setting the attribute sparseness to data or components. Sparse components lead to localized features, and sparse data leads to a more efficient representation of the data.
Examples:
References:
- “Learning the parts of objects by non-negative matrix factorization” D. Lee, S. Seung, 1999
- “Non-negative Matrix Factorization with Sparseness Constraints” P. Hoyer, 2004
- “Projected gradient methods for non-negative matrix factorization” C.-J. Lin, 2007
- “SVD based initialization: A head start for nonnegative matrix factorization” C. Boutsidis, E. Gallopoulos, 2008